GPU nodes
To support the latest computing advancements in many fields of science, Sherlock features a number of compute nodes with GPUs that can be used to run a variety of GPU-accelerated applications. Those nodes are available to everyone, but are a scarce, highly-demanded resource, so getting access to them may require some wait time in queue.
Getting your own GPU nodes
If you need frequent access to GPU nodes, we recommend considering becoming an owner on Sherlock, so you can have immediate access to your GPU nodes when you need them.
GPU nodes#
A limited number of GPU nodes are available in the gpu partition. Anybody running on Sherlock can submit a job there. As owners contribute to expand Sherlock, more GPU nodes are added to the owners partition, for use by PI groups which purchased their own compute nodes.
There are a variety of different GPU configuration available in the gpu partition. To see the available GPU types, please see the GPU types section.
Submitting a GPU job#
To submit a GPU job, you'll need to use the --gpus (or -G) option in your batch script or command line submission options.
For instance, the following script will request one GPU for two hours in the gpu partition, and run the GPU-enabled version of gromacs:
#!/bin/bash
#SBATCH -p gpu
#SBATCH -c 10
#SBATCH -G 1
ml load gromacs/2016.3
srun gmx_gpu ...
You can also directly run GPU processes on compute nodes with srun. For instance, the following command will display details about the GPUs allocated to your job:
$ srun -p gpu --gpus 2 nvidia-smi
Fri Jul 28 12:41:49 2017
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 375.51 Driver Version: 375.51 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P40 On | 0000:03:00.0 Off | 0 |
| N/A 26C P8 10W / 250W | 0MiB / 22912MiB | 0% E. Process |
+-------------------------------+----------------------+----------------------+
| 1 Tesla P40 On | 0000:04:00.0 Off | 0 |
| N/A 24C P8 10W / 250W | 0MiB / 22912MiB | 0% E. Process |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
GPU resources MUST be requested explicitly
Jobs will be rejected at submission time if they don't explicitly request GPU resources.
The gpu partition only accepts jobs explicitly requesting GPU resources. If they don't, they will be rejected with the following message:
$ salloc -p gpu
srun: error: Unable to allocate resources: Job violates accounting/QOS policy (job submit limit, user's size and/or time limits)
Interactive sessions#
As for any other compute node, you can submit an interactive job and request a shell on a GPU node with the following command:
$ salloc -p gpu --gpus 1
salloc: job 38068928 queued and waiting for resources
salloc: job 38068928 has been allocated resources
$ nvidia-smi --query-gpu=index,name --format=csv,noheader
0, Tesla V100-SXM2-16GB
Instant lightweight GPU instances#
Given that some tasks don't necessarily require a full-fledged, top-of-the-line GPU, lightweight GPU instances are provided to allow instant access to GPU resources for quick debugging, prototyping or testing jobs.
Lightweight GPU instances
Lightweight GPU instances leverage NVIDIA’s Multi-Instance GPU (MIG) to provide multiple fully isolated GPU instances on the same physical GPU, each with their own high-bandwidth memory, cache, and compute cores.
Those GPU instances are instantly available via the dev partition, and can be requested with the sh_dev command:
# sh_dev -g 1
[...]
[kilian@sh03-17n15 ~] (job 17628407) $ nvidia-smi -L
GPU 0: NVIDIA A30 (UUID: GPU-ac772b5a-123a-dc76-9480-5998f435fe84)
MIG 1g.6gb Device 0: (UUID: MIG-87e5d835-8046-594a-b237-ccc770b868ef)
For interactive apps in the Sherlock OnDemand interface, requesting a GPU in the dev partition will initiate an interactive session with access to a lightweight GPU instance.
GPU types#
Since Sherlock features many different types of GPUs, each with its own technical characteristics, performance profiles and specificities, you may want to ensure that your job runs on a specific type of GPU.
To that end, Slurm allows users to specify constraints when submitting jobs, which will indicate the scheduler that only nodes having features matching the job constraints could be used to satisfy the request. Multiple constraints may be specified and combined with various operators (please refer to the official Slurm documentation for details).
The list of available features on compute nodes can be obtained with the node_feat1 command. And more specifically, to list the GPU-related features of nodes in the gpu partition::
$ node_feat -p gpu | grep GPU_
GPU_BRD:TESLA
GPU_GEN:PSC
GPU_MEM:16GB
GPU_MEM:24GB
GPU_SKU:TESLA_P100_PCIE
GPU_SKU:TESLA_P40
You can use node_feat without any option to list all the features of all the nodes in all the partitions. But please note that node_feat will only list the features of nodes from partitions you have access to, so output may vary depending on your group membership.
The different characteristics2 of various GPU types are listed in the following table
| Slurm feature | Description | Possible values | Example job constraint |
|---|---|---|---|
GPU_BRD | GPU brand | GEFORCE: GeForce / TITANTESLA: Tesla | #SBATCH -C GPU_BRD:TESLA |
GPU_GEN | GPU generation | PSC: PascalMXW: Maxwell | #SBATCH -C GPU_GEN:PSC |
GPU_MEM | Amount of GPU memory | 16GB, 24GB | #SBATCH -C GPU_MEM:16GB |
GPU_SKU | GPU model | TESLA_P100_PCIETESLA_P40 | #SBATCH -C GPU_SKU:TESLA_P40 |
Depending on the partitions you have access to, more features may be available to be requested in your jobs.
For instance, to request a Tesla GPU for you job, you can use the following submission options:
$ srun -p gpu -G 1 -C GPU_BRD:TESLA nvidia-smi -L
GPU 0: Tesla P100-SXM2-16GB (UUID: GPU-4f91f58f-f3ea-d414-d4ce-faf587c5c4d4)
Unsatisfiable constraints
If you specify a constraint that can't be satisfied in the partition you're submitting your job to, the job will be rejected by the scheduler. For instance, requesting a RTX3090 GPU in the gpu partition, which doesn't feature any, will result in an error:
For more information about requesting specific node features and adding job constraints, you can also refer to the "Node features" page.
GPU compute modes#
By default, GPUs on Sherlock are set in the Exclusive Process compute mode3, to provide the best performance and an isolated environment for jobs, out of the box.
Some software may require GPUs to be set to a different compute mode, for instance to share a GPU across different processes within the same application.
To handle that case, we developed a specific option, --gpu_cmode, that users can add to their srun and sbatch submission options, to choose the compute mode for the GPUs allocated to their job.
Here's the list of the different compute modes supported on Sherlock's GPUs:
| GPU compute mode | --gpu_cmode option | Description |
|---|---|---|
| "Default" | shared | Multiple contexts are allowed per device (NVIDIA default) |
| "Exclusive Process" | exclusive | Only one context is allowed per device, usable from multiple threads at a time (Sherlock default) |
| "Prohibited" | prohibited | No CUDA context can be created on the device |
By default, or if the --gpu_cmode option is not specified, GPUs will be set in the "Exclusive Process" mode, as demonstrated by this example command:
$ srun -p gpu -G 1 nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 387.26 Driver Version: 387.26 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P40 On | 00000000:03:00.0 Off | 0 |
| N/A 22C P8 10W / 250W | 0MiB / 22912MiB | 0% E. Process |
+-------------------------------+----------------------+----------------------+
With the --gpu_cmode option, the scheduler will set the GPU compute mode to the desired value before execution:
$ srun -p gpu -G 1 --gpu_cmode=shared nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 387.26 Driver Version: 387.26 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P40 On | 00000000:03:00.0 Off | 0 |
| N/A 22C P8 10W / 250W | 0MiB / 22912MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
Tip
"Default" is the name that the NVIDIA System Management Interface (nvidia-smi) uses to describe the mode where a GPU can be shared between different processes. It does not represent the default GPU compute mode on Sherlock, which is "Exclusive Process".
Advanced options#
A number of submission options are available when submitting GPU jobs, to request specific resource mapping or task binding options.
Here are some examples to allocate a set of resources as a function of the number of requested GPUs:
-
--cpus-per-gpu: requests a number of CPUs per allocated GPU.For instance, the following options will allocate 2 GPUs and 4 CPUs:
-
--gpus-per-node: requests a number of GPUs per node, --gpus-per-task: requests a number of GPUs per spawned task,--mem-per-gpu: allocates (host) memory per allocated GPU.
Other options can help set particular GPU properties (topology, frequency...):
-
--gpu-bind: specify task/GPU binding mode.By default every spawned task can access every GPU allocated to the job. This option can help making sure that tasks are bound to the closest GPU, for better performance.
-
--gpu-freq: specify GPU and memory frequency. For instance:
Those options are all available to the srun/sbatch/salloc commands, and more details about each of them can be found in the Slurm documentation.
Conflicting options
Given the multitude of options, it's very easy to submit a job with conflicting options. In most cases the job will be rejected.
For instance:
Here, the first two options implicitly setcpu-per-task to 2, while the third option explicitly sets cpus-per-task to 1. So the job's requirements are conflicting and can't be satisfied. Environment and diagnostic tools#
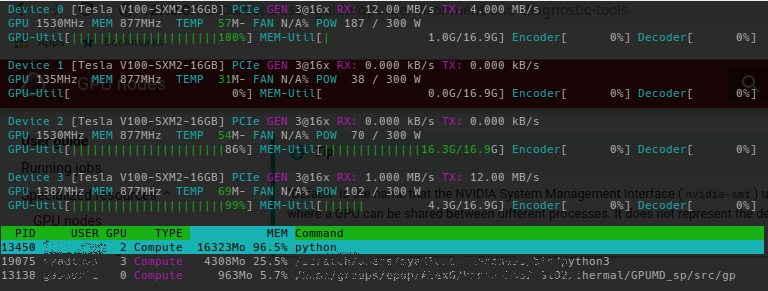
nvtop#
GPU usage information can be shown with the nvtop tool. nvtop is available as a module, which can be loaded like this:
nvtop provides an htop-like interactive view of GPU utilization. Users can monitor, estimate and fine tune their GPU resource requests with this tool. Percent GPU and memory utilization is shown as a user's GPU code is running.
-
See
node_feat -hfor more details. ↩ -
The lists of values provided in the table are non exhaustive. ↩
-
The list of available GPU compute modes and relevant details are available in the CUDA Toolkit Documentation ↩